
Xilinx FPGA 使可扩展 MIMO 预编码核心
2016 年 8 月 17 日
在贝尔实验室爱尔兰研究人员建立了与广义基于 MIMO 无线通信系统的高性能 Fpga 的频率依赖预编码核心。
大规模 MIMO (多输入,多输出) 的无线通信系统已上升到最前沿作为 5 G 无线网络的首选的基础体系结构。低延迟预编码实现方案对于享受多传输体系结构所固有的多输入多输出方法至关重要。我们的团队建高速、 低延迟的预编码核心 Xilinx 系统发电机组和简单、 可扩展 Vivado 设计套件。
由于他们内在多用户空间复用传输能力,大规模 MIMO 系统大大增加在旧式单天线用户设备和进化的多天线用户终端信号-到-干扰-和信噪比。其结果是更多的网络容量、 更高的数据吞吐量和效率更高的频谱利用率。
但每棒两端,并大规模 MIMO 技术也是如此。若要使用它,电信工程师需要建立多个射频收发器和基于辐射的相控阵列的多个天线。他们还必须利用数字马力执行所谓的预编码功能。
我们的解决方案是打造低延迟和可扩展频率依赖预编码片断的知识产权 (IP),可以使用乐高的方式既集中式和分布式大规模 MIMO 架构。这个 DSP 研发项目的关键是高性能赛灵思 7 系列 Fpga 和 Xilinx 的 Vivado 设计套件 2015.1 系统发电机与 MATLAB/Simulink。
广义的 MIMO 系统中预编码
在蜂窝网络中,从广义 MIMO 发射机辐射的用户数据流会”塑造”空气由所谓的信道响应每个发射器和接收器在特定频率之间。换句话说,不同的数据流会通过不同的路径,到达接收器领空的另一端。甚至同一个数据流会因为举止反常不同的”经验”在频率域中。
这种固有的无线传输现象是等价于特定频率响应的有限冲激响应 (FIR) 滤波器应用于每个数据流,导致系统性能低下由于引入频率”失真”的无线信道。如果我们对无线信道作为一个大的黑色盒子,只能输入 (变送器输出) 和输出 (接收器输入) 是明显在系统级别。
我们实际上可以在 MIMO 发射机边与反演信道响应以 precompensate 通道黑框效果,添加预均衡黑箱,然后串级系统将提供合理”矫正”数据流在接收器设备。
我们称此预均衡方法预编码,这基本上意味着施加一组”整形”系数在发射机链。例如,如果我们打算传输 NRX 独立数据流 NTX (数目变送器) 天线,我们将需要执行预编码的 NRX × NTX 临时复杂线性卷积运算的成本和相应的将操作组合到空气辐射 NTX 射频信号之前的预均衡。
一个简单的低延迟实现的复杂的线性卷积是 FIR 型复杂离散数字滤波器在时间域中。
系统功能要求
在创建一个低延迟预编码 IP 核心的使命,我的团队面临几个基本要求。
- 我们不得不进多分支并行数据流具有不同的系数集 precode 一个数据流。
- 我们需要将有 100 多个水龙头长复杂不对称 FIR 功能放在每个分支提供合理的预编码性能。
- 预编码系数需要经常更新。
- 必须容易更新和扩展以支持不同的可扩展系统体系结构设计的核心。
- 预延迟时间应该是在给定的资源约束条件以尽可能低的水平。
此外,除了参加到一个特定的设计的功能要求,我们都必须小心的硬件资源的限制。换句话说,创建一个资源友好型算法实现将有利于关键有限硬件资源,例如 DSP48s,Xilinx Fpga 上微妙的硬件乘法器。
高速低延迟预编码 (HLP) 核心设计
可伸缩性在本质上是一个关键的功能,必须先解决问题,你开始设计这种性质。可扩展的设计将使长期可持续基础设施演变和在短期内导致最优、 经济高效的部署策略。可伸缩性来自模块化。按照这个思路,我们在 Xilinx 系统发电机与 Simulink 中创建模块化通用复杂 FIR 滤波器评价平台。


图 1 顶级系统体系结构
图 1 说明了顶级的系统体系结构。SimulinkHLPcore 描述离散数字筛选器块中 Simulink,总长复杂 FIR 滤波器,而 FPGAHLPcore 实现了多分支复 FIR 滤波器与系统发电机 Xilinx 资源块,如图 2 所示。

Xilinx 资源块体系统发电机
不同杉木实现体系结构导致不同的 FPGA 的资源利用率。表 1 比较了在 128 水龙头复杂不对称 FIR 滤波器在不同的实现体系结构中使用的复杂乘数 (厘米)。我们假设 I/Q 数据速率是 30.72 Msamples/秒 (20-MHz-带宽 LTE 先进的信号)。
完整的并行实现体系结构是根据直接向其简单映射相当简单-我 FIR 体系结构,但它使用了大量厘米资源。全串行执行体系结构通过共享相同的厘米单位与 128 操作以时分复用 (TDM) 方式,使用厘米资源最少,但为国家先进 FPGA 在不可能的时钟速度运行。
一个实用的解决方案是选择部分并行执行的体系结构,将序贯长过滤器链拆分成几个节段性并行阶段。两个例子如表 1 所示。
表 1 复杂乘数 (厘米) 使用率比较 128 水龙头复杂的非对称 FIR 完全并行全串行部分并行-A * 部分平行 B 需要 Fclk (MHz) 30.72 x 1 = 30.72 30.72 x 128 = 3932.16 30.72 x 16 = 491.52 30.72 x 8 = 2576 1 分支 LC 核心 128 厘米 1 厘米 8 厘米 16 厘米 4 分支 LC 核心 512 厘米 4 厘米 32 厘米 64 厘米 * 建议高速度低延迟预编码 (HLP) 核心体系结构。 我们去计划 A 最小厘米利用及其合理的时钟速率。我们实际上可以通过操纵数据速率、 时钟频率和数量的顺序阶段从而确定最终的体系结构︰
FCLK = FDATA × NTAP÷NSS
其中 NTAP 和 NSS 表示过滤器和序贯阶段数目的长度。 然后我们创建了三个主要模块︰ 系数存储模块︰ 我们利用高性能双端口块只公羊来存储需要加载到 FIR 系数公羊的智商系数。用户可以选择何时将上载到此存储系数以及何时更新的 FIR 滤波器的系数由 wr 和 rd 控制信号。数据 TDM 流水线模块︰ 我们多路复用传入的 IQ 数据在 30.72 MHz 采样率,以创建八流水线 (NSS = 8) 数据流 30.72 高采样率 × 128÷8 = 491.52 MHz。然后我们就这些数据流送入四分公司线性卷积 (4B-LC) 模块。4B-LC 模块︰ 此模块包含四个独立复杂 FIR 滤波器的供应链,每个相同的部分并行体系结构与实现。例如,图 3 所示 1 处。  图 3 FIR 滤波器链分支分支 1 包括四个 subprocessing 阶段分离由寄存器为更好的时机︰ FIR 系数 RAM (补习班) 顺序写入和并行读取的阶段;一个复杂乘法阶段;一个复数加法阶段;和一个节段的积累和缩减像素采样阶段。为了尽量减少核心的 I/O 数,我们第一阶段涉及创建顺序写入操作系数从存储加载到 FIR 补习班在 TDM 方式 (每个补习班包含 16 = 128/8 智商系数)。我们设计 FIR 系数同时喂厘米核心并行读取的操作。在复杂乘法阶段,以尽量减少 DSP48 利用率,我们选择了高效、 全面的流水线三乘数体系结构来执行复杂的乘法在成本的六个时间周期的延迟。接下来,复数加法阶段聚合到单个流 CMs 的产出。最后,节段性的积累和缩减像素采样阶段积累的临时 substreams 为 16 的时间周期,以获得相应的线性卷积结果 128 抽头 FIR 滤波器,并缩减像素采样到高速流回去匹配系统的数据采样率 — — 在这里,30.72 MHz.设计验证我们分两步执行 IP 验证。首先,我们比较与双精度的多分支冷杉,核心在 Simulink,引用 FPGAHLPcore 的输出和发现,我们取得了相对振幅误差小于 0.04 %16 位分辨率版本。较宽的数据将提供更好的性能,以更多的资源。 经过验证的功能,它是时间来验证的硅性能。所以我们第二步是合成和在 Vivado 设计套件 2015.1 针对 Zynq 7000 所有可编程 SoC (Kintex® xc7k325tffg900-2 设备) 的 FPGA 结构中实现创建的 IP。与完整的层次结构中的工具的综合设置和默认执行设置,很容易实现 491.52 MHz 内部处理时钟速度快,所需的时间,因为我们有明确的注册层次结构创建全面的流水线设计。可伸缩性的插图的 HLP IP 我们设计可以很容易用于创建较大的大规模 MIMO 预编码核心。表二列出所选的应用场景,与关键资源 utilisations。
图 3 FIR 滤波器链分支分支 1 包括四个 subprocessing 阶段分离由寄存器为更好的时机︰ FIR 系数 RAM (补习班) 顺序写入和并行读取的阶段;一个复杂乘法阶段;一个复数加法阶段;和一个节段的积累和缩减像素采样阶段。为了尽量减少核心的 I/O 数,我们第一阶段涉及创建顺序写入操作系数从存储加载到 FIR 补习班在 TDM 方式 (每个补习班包含 16 = 128/8 智商系数)。我们设计 FIR 系数同时喂厘米核心并行读取的操作。在复杂乘法阶段,以尽量减少 DSP48 利用率,我们选择了高效、 全面的流水线三乘数体系结构来执行复杂的乘法在成本的六个时间周期的延迟。接下来,复数加法阶段聚合到单个流 CMs 的产出。最后,节段性的积累和缩减像素采样阶段积累的临时 substreams 为 16 的时间周期,以获得相应的线性卷积结果 128 抽头 FIR 滤波器,并缩减像素采样到高速流回去匹配系统的数据采样率 — — 在这里,30.72 MHz.设计验证我们分两步执行 IP 验证。首先,我们比较与双精度的多分支冷杉,核心在 Simulink,引用 FPGAHLPcore 的输出和发现,我们取得了相对振幅误差小于 0.04 %16 位分辨率版本。较宽的数据将提供更好的性能,以更多的资源。 经过验证的功能,它是时间来验证的硅性能。所以我们第二步是合成和在 Vivado 设计套件 2015.1 针对 Zynq 7000 所有可编程 SoC (Kintex® xc7k325tffg900-2 设备) 的 FPGA 结构中实现创建的 IP。与完整的层次结构中的工具的综合设置和默认执行设置,很容易实现 491.52 MHz 内部处理时钟速度快,所需的时间,因为我们有明确的注册层次结构创建全面的流水线设计。可伸缩性的插图的 HLP IP 我们设计可以很容易用于创建较大的大规模 MIMO 预编码核心。表二列出所选的应用场景,与关键资源 utilisations。
表 2 示例资源运用在不同的应用场景中基于建议高速度低延迟预编码核心大规模 MIMO 配置 (Nrx x Ntx) 数量的 HLP 药芯复杂乘数分布式内存 (kb) 的内存块 (RAM18E) 4 x 4 4 128 16 4 4 x 8 8 256 32 8 4 16 16 512 64 16 x 4 x 32 32 1024年 128 32 x 8 16 512 64 16 8 8 16 32 1024年 128 32 你将需要额外的聚合阶段到 x 提供的最后的预编码结果。例如,如图 4 所示,它很容易建立预核心编码通过插入四个 HLP 芯和一个额外流水线的数据聚合阶段 4 x 4。 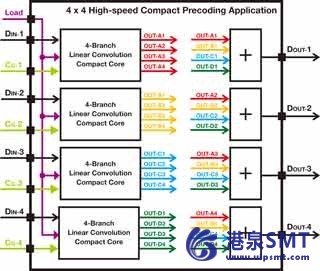 图 4 4 × 4 MIMO 预编码核心结论我们已经演示了如何快速构建高效、 可伸缩 DSP 线性卷积中的应用程序形式的大规模 MIMO 预编码核心与 Xilinx 系统发电机和 Vivado 设计工具。您可以展开这一核心支持长抽头 FIR 应用程序通过在部分并行的体系结构中,使用多个连续阶段或合理地增加处理时钟速率更快做好。对于后一种情况,它将有助于查明瓶颈和关键路径的关于实际执行体系结构的目标设备。然后,协同优化的硬件和算法将一个好的方法来优化系统性能,如关于硬件使用率更紧凑的预编码算法的开发。最初,我们专注于预编码的解决方案和最低的延迟。为我们下一步,我们要探索更好的资源利用率和功率消耗的替代解决方案。
图 4 4 × 4 MIMO 预编码核心结论我们已经演示了如何快速构建高效、 可伸缩 DSP 线性卷积中的应用程序形式的大规模 MIMO 预编码核心与 Xilinx 系统发电机和 Vivado 设计工具。您可以展开这一核心支持长抽头 FIR 应用程序通过在部分并行的体系结构中,使用多个连续阶段或合理地增加处理时钟速率更快做好。对于后一种情况,它将有助于查明瓶颈和关键路径的关于实际执行体系结构的目标设备。然后,协同优化的硬件和算法将一个好的方法来优化系统性能,如关于硬件使用率更紧凑的预编码算法的开发。最初,我们专注于预编码的解决方案和最低的延迟。为我们下一步,我们要探索更好的资源利用率和功率消耗的替代解决方案。